Org-Roam to Cosmascope
Firstly my org-roam db is small, its limited. I cannot quite seem to get my head around the concept but I love the visualisation provided by org-roam-ui it reminds me of when I used TheBrain many years ago.
What this does is converts your org-roam files into a format usable by cosmascope so that you can share them, host them on your site but consider it an experiment firstly in using ChatGPT & secondly to see if it was possible to convert org-roam into a usable graph via cosmascope1. This is adapted from Kévin Polisano’s obsidian2cosma.py (https://github.com/kevinpolisano/obsidian2cosma) which converts your Obsidian vault. It is only the first step, you must then create the cosmascope itself.
Consider this as work in progress and to be improved! There are limitations
- cosmascope will not display images if linked in your text
- the script does not handle internal links well ie in the generated log you may see
The following paragraph contains a broken link "[[49F6458C-14AA-4C4B-9F6B-7F007E2199F9|emacs again?]]"- I’m sure there will be other issues but for an experiment and a test on a small org-roam data set it worked quite well.
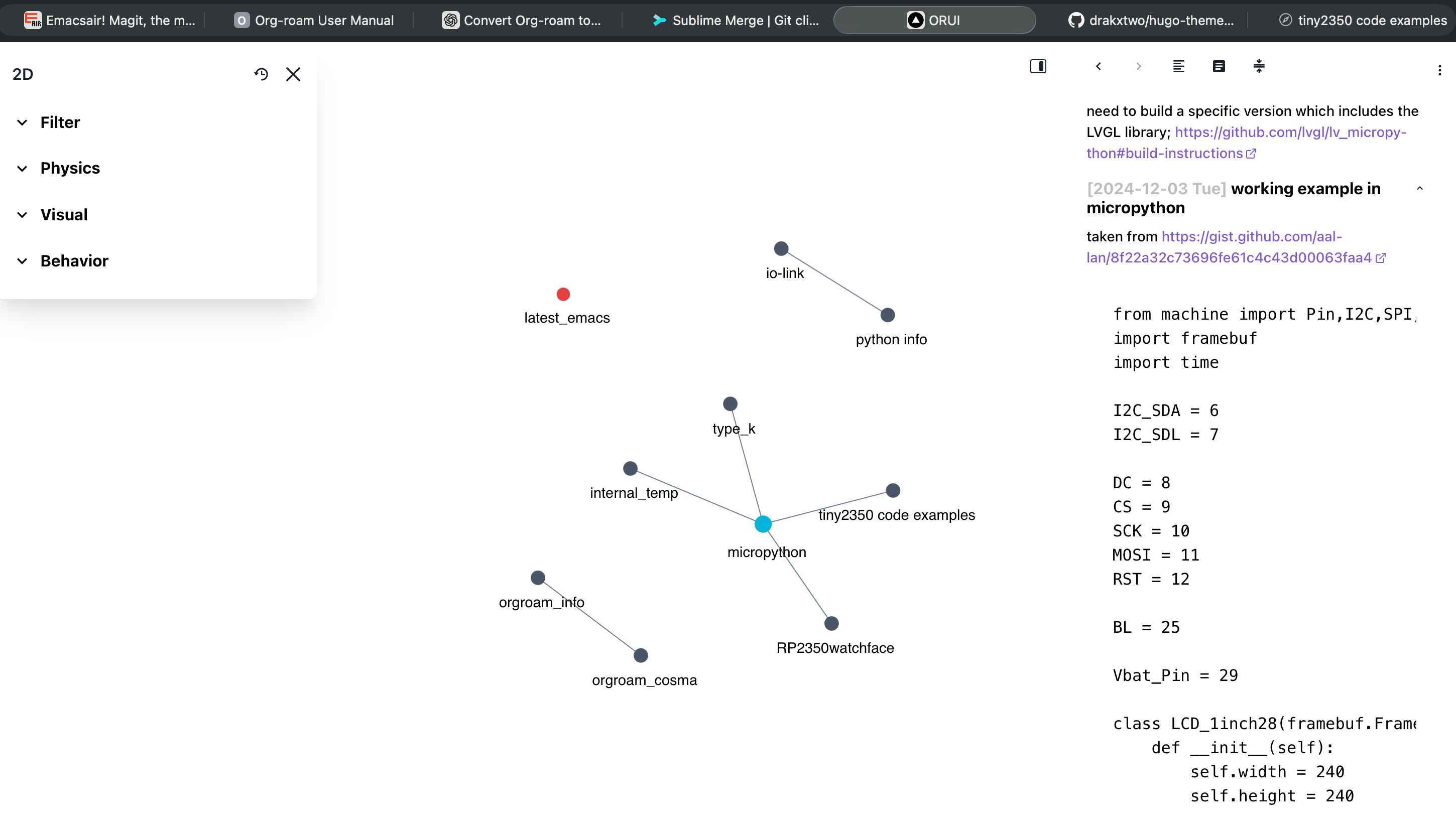
Figure 1: Org-roam-ui screenshot
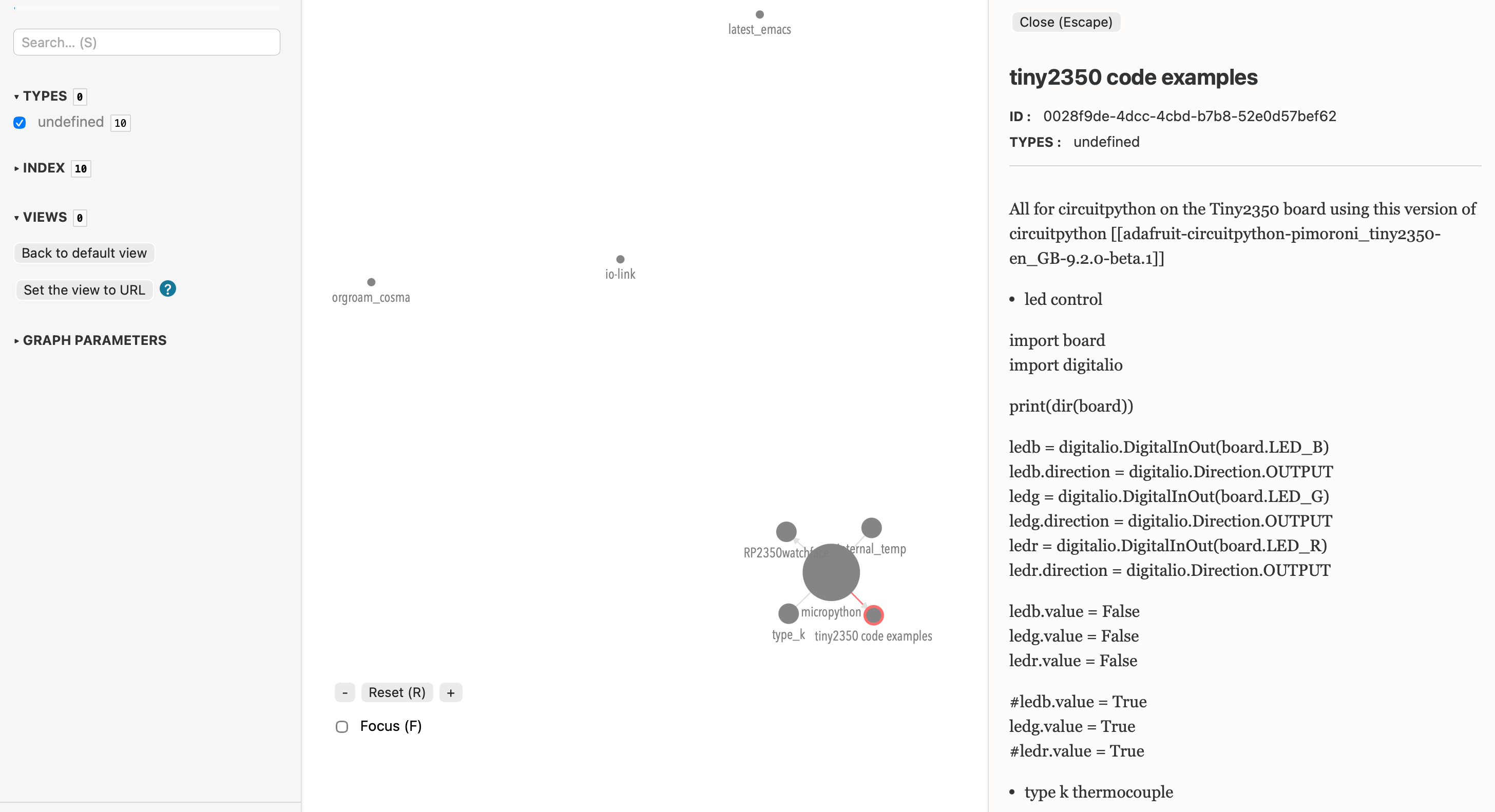
Figure 2: Converted org-roam to cosmoscope
The script is located here on my rarely used github https://github.com/drakxtwo/orgroam_cosmascope
but a copy is also below however only the github one will be updated.
python code snippet start
"""
Convert an Org-roam vault into a collection of Markdown notes readable by Cosma (https://cosma.graphlab.fr/en/)
Usage:
python orgroam2cosma.py -i input_folder_path -o output_folder_path
[--type TYPE] [--tags TAGS]
[--creationdate CREATIONDATE]
[--zettlr True]
[-v]
Example:
python orgroam2cosma.py -i ~/org-roam -o ./cosma_notes --zettlr True --verbose
Author: adapted from Kévin Polisano’s obsidian2cosma.py by ChatGPT
License: GNU GPL v3.0
"""
import os
import re
import platform
import argparse
import shutil
import unicodedata
import csv
from pathlib import Path
from datetime import datetime as dt
# ========== Argument parsing ==========
parser = argparse.ArgumentParser()
parser.add_argument("-i", "--input", help="Path to the input folder", required=True)
parser.add_argument("-o", "--output", help="Path to the output folder", required=True)
parser.add_argument("--tags", help="Filter notes by tags", default=None)
parser.add_argument("--creationdate", help="Use file creation date for IDs", default=False)
parser.add_argument("--zettlr", help="Use Zettlr-style links [text]([[id]])", default=False)
parser.add_argument("-v", "--verbose", action="store_true", help="Verbose mode")
args = parser.parse_args()
input_folder = args.input
output_folder = args.output
def printv(text):
if args.verbose:
print(text)
# ========== Helper functions ==========
def creation_date(file):
if platform.system() == "Windows":
return os.path.getctime(file)
else:
stat = os.stat(file)
try:
return stat.st_birthtime
except AttributeError:
return stat.st_mtime
def create_id(file):
timestamp = creation_date(file) if args.creationdate else dt.now().timestamp()
return dt.fromtimestamp(timestamp).strftime('%Y%m%d%H%M%S')
def clean_filename(name):
name = unicodedata.normalize("NFD", name).encode("ascii", "ignore").decode("utf-8")
return name.replace(" ", "-")
# ========== Org file parsing ==========
def parse_org_frontmatter(content):
"""Extracts title, tags, and id from Org file headers."""
title_match = re.search(r"^#\+title:\s*(.+)$", content, re.MULTILINE)
tags_match = re.search(r"^#\+filetags:\s*:?(.+?):?$", content, re.MULTILINE)
id_match = re.search(r"^:ID:\s*(.+)$", content, re.MULTILINE)
roamkey_match = re.search(r"^#\+roam_key:\s*(.+)$", content, re.MULTILINE)
title = title_match.group(1).strip() if title_match else None
tags = []
if tags_match:
tags = [t.strip() for t in tags_match.group(1).split(":") if t.strip()]
id_ = id_match.group(1).strip() if id_match else None
if not id_ and roamkey_match:
id_ = roamkey_match.group(1).strip()
return {"title": title, "tags": tags, "id": id_}
def convert_org_links(content, title2id):
"""Convert Org links [[id:xxxx][Label]] or [[file:note.org][Label]] to Cosma Markdown links."""
def repl(match):
target = match.group(1)
label = match.group(2) or match.group(1)
# Org id link: [[id:1234][Label]]
if target.startswith("id:"):
id_ = target.replace("id:", "")
return f"[{label}]([[{id_}]])" if args.zettlr else f"[[{id_}|{label}]]"
# Org file link: [[file:note.org][Label]]
elif target.startswith("file:"):
file_ref = Path(target.replace("file:", "")).stem
file_ref = clean_filename(file_ref)
if file_ref in title2id:
id_ = title2id[file_ref]
return f"[{label}]([[{id_}]])" if args.zettlr else f"[[{id_}|{label}]]"
else:
return f"[[{label}]]"
# Normal URL or external link
elif re.match(r"https?://", target):
return f"[{label}]({target})"
return f"[[{label}]]"
# Replace all Org-style links [[target][label]]
content = re.sub(r"\[\[([^\]]+?)\](?:\[([^\]]+)\])?\]", repl, content)
return content
def convert_images(content):
"""Convert [[file:img.png]] to """
return re.sub(r"\[\[file:(.+?\.(?:png|jpg|jpeg|gif))\]\]", r"", content)
# ========== Main pipeline ==========
def main():
Path(output_folder).mkdir(parents=True, exist_ok=True)
printv(f"Converting Org-roam notes from {input_folder} → {output_folder}")
title2id = {}
org_files = []
# Step 1: collect files
for root, _, files in os.walk(input_folder):
for f in files:
if f.endswith(".org"):
org_files.append(os.path.join(root, f))
# Step 2: extract metadata and create IDs
for f in org_files:
print(f)
with open(f, "r", encoding="utf-8") as infile:
print(infile.read())
content = infile.read()
meta = parse_org_frontmatter(content)
title = meta["title"] or Path(f).stem
id_ = meta["id"] or create_id(f)
title2id[clean_filename(title)] = id_
# Step 3: process and export each file
for f in org_files:
with open(f, "r", encoding="utf-8") as infile:
content = infile.read()
meta = parse_org_frontmatter(content)
title = meta["title"] or Path(f).stem
id_ = meta["id"] or title2id[clean_filename(title)]
tags = meta["tags"]
# Convert links & images
content = convert_org_links(content, title2id)
content = convert_images(content)
# Remove Org metadata lines
content = re.sub(r"^#\+.*$", "", content, flags=re.MULTILINE)
content = re.sub(r"^:PROPERTIES:[\s\S]*?:END:", "", content, flags=re.MULTILINE)
content = content.strip()
# YAML front matter
frontmatter = "---\n"
frontmatter += f"title: {title}\n"
frontmatter += f"id: {id_}\n"
if tags:
frontmatter += f"tags: [{', '.join(tags)}]\n"
frontmatter += "---\n\n"
md_content = frontmatter + content + "\n"
out_name = clean_filename(Path(title).stem) + ".md"
out_path = os.path.join(output_folder, out_name)
with open(out_path, "w", encoding="utf-8") as outfile:
outfile.write(md_content)
printv(f"[OK] {os.path.basename(f)} → {out_name}")
# Step 4: save title→id mapping
with open(os.path.join(output_folder, "_title2id.csv"), "w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerows(title2id.items())
printv(f"✅ Conversion complete! {len(org_files)} notes processed.")
if __name__ == "__main__":
main()python code snippet end
-
Cosmascope (https://cosma.arthurperret.fr) describes itself as a knowledge visualisation tool for knowledge workers and it allows you to create an HTML page which displays much like org-roam-ui or obsidians graph. ↩︎